データ匿名化
データ匿名化
データ匿名化とは、ユーザーが入力した個人識別情報(PII)を匿名化するプロセスを指し、機密性の高いユーザー情報がLLMサービスからアクセスできないようにし、ユーザーのプライバシーを保護します。
プロセス
loading...
graph LR
Input[入力] --> Anonymization[匿名化] --> LLM --> Deanonymization[非匿名化] --> Output[出力]
設定
現在、Microsoft Presidio匿名化サービスのみが利用可能です。
グループ
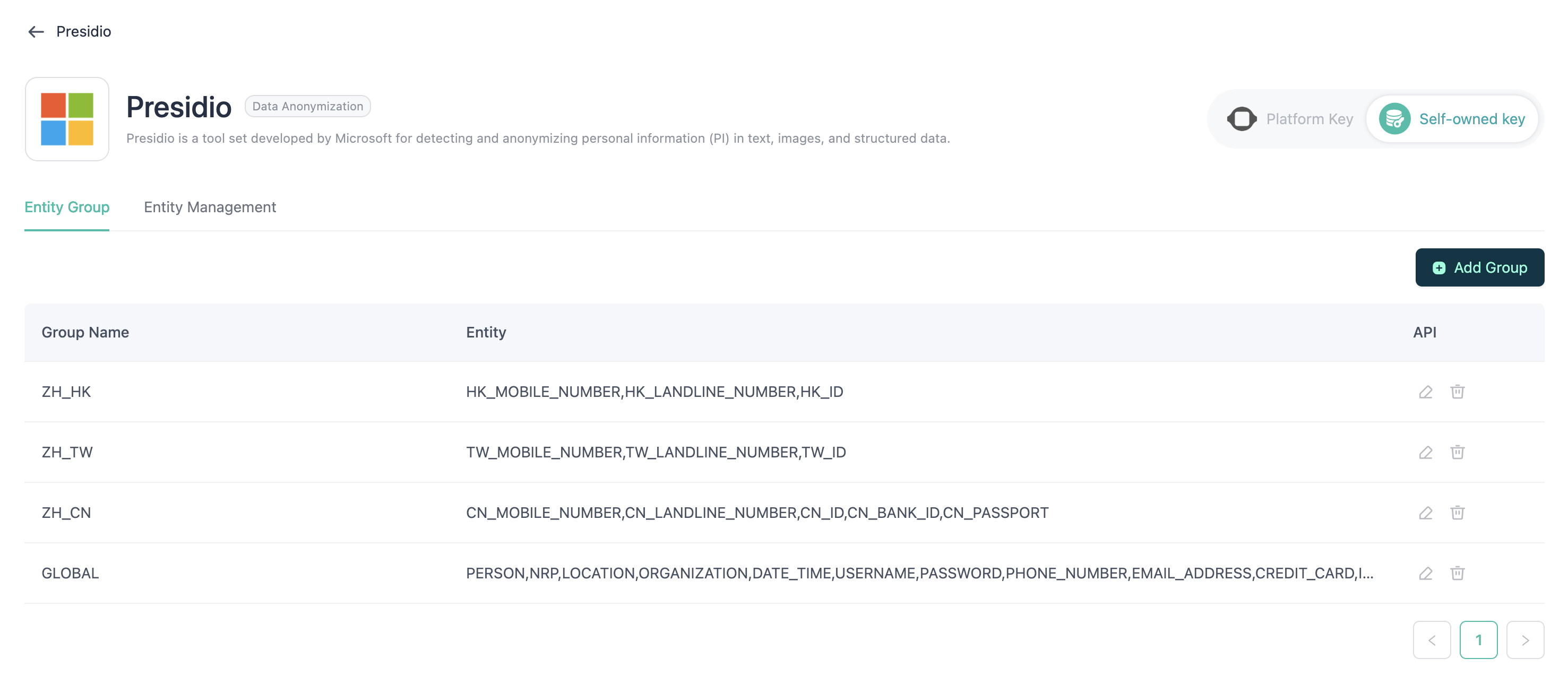
異なるエンティティを個別のカテゴリにグループ化することで、エージェント内での選択と使用が容易になります。
エンティティ
エンティティは匿名化の対象を指します。GPTBotsには一般的に使用されるエンティティセットが組み込まれていますが、ユーザーが様々な匿名化ニーズに対応するためにカスタムエンティティを定義することも可能です。
新しいエンティティ
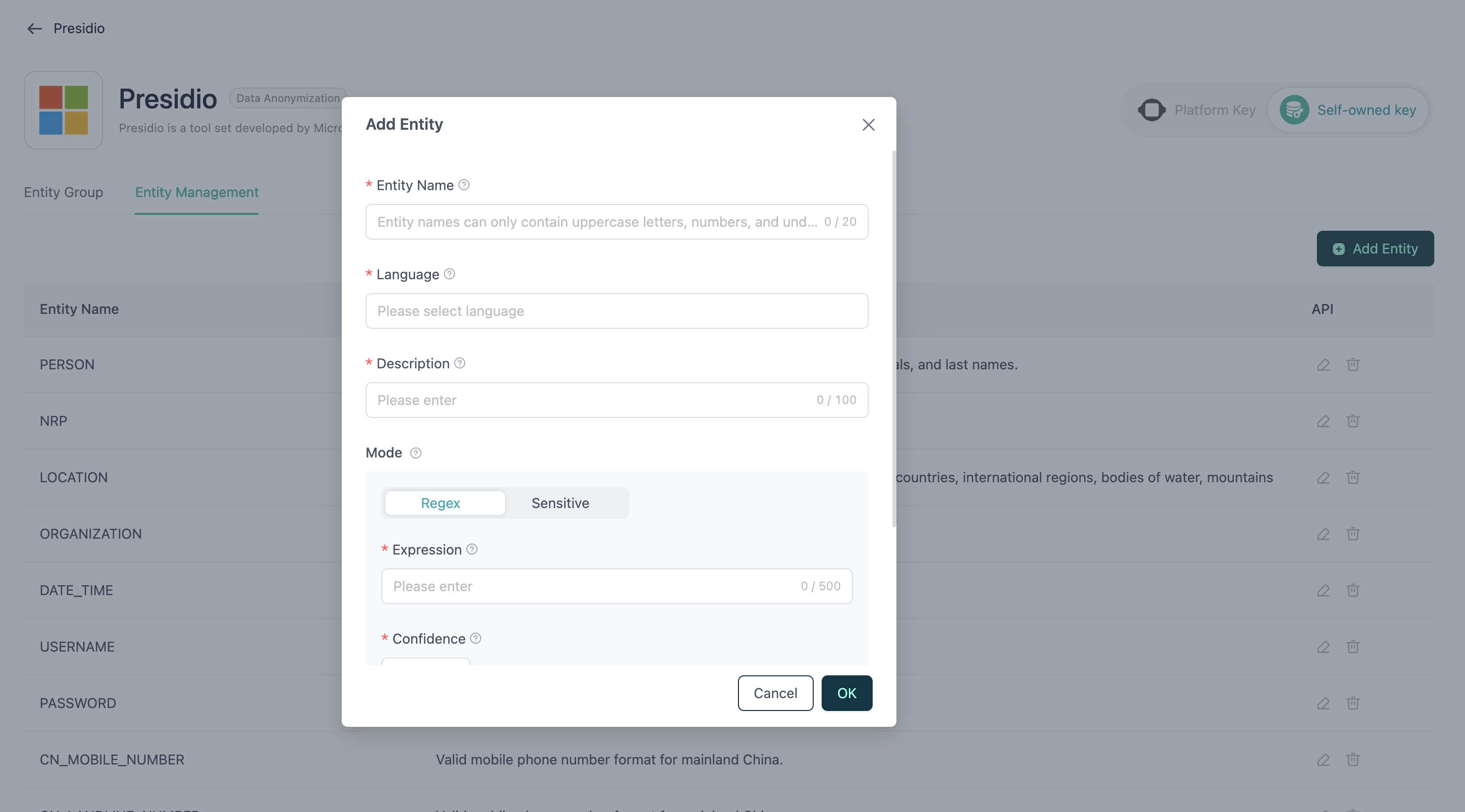
- 名前: エンティティの名前。大文字とアンダースコアのみ含むことができます。
- 言語: エンティティがサポートする言語。単一のエンティティで複数の言語をサポートできます。
- 説明: エンティティの簡単な紹介または説明。
- 正規表現パターン: エンティティにマッチするために使用される正規表現。
- スコア(信頼度): マッチの信頼度レベル、0.0から1.0の範囲。
- センシティブワード: テキスト内に存在する場合、このエンティティとして識別される正確な単語またはフレーズのリスト。
- コンテキスト: マッチングスコアの向上に役立つコンテキストキーワードのリスト。これらの単語がテキスト内の潜在的なマッチの近くに表示される場合、Presidioはそのマッチにより高い信頼度スコアを割り当てます。