Anonimización de datos
La anonimización de datos es el proceso de anonimizar la información de identificación personal (PII, por sus siglas en inglés) introducida por los usuarios, lo que garantiza que la información sensible del usuario no sea accesible para los servicios de modelos de lenguaje (LLM) y protege la privacidad del usuario.
Proceso
graph LR
Input --> Anonymization --> LLM --> Deanonymization --> Output
Configuración
Actualmente, solo está disponible el servicio de anonimización de Microsoft Presidio.
Grupo
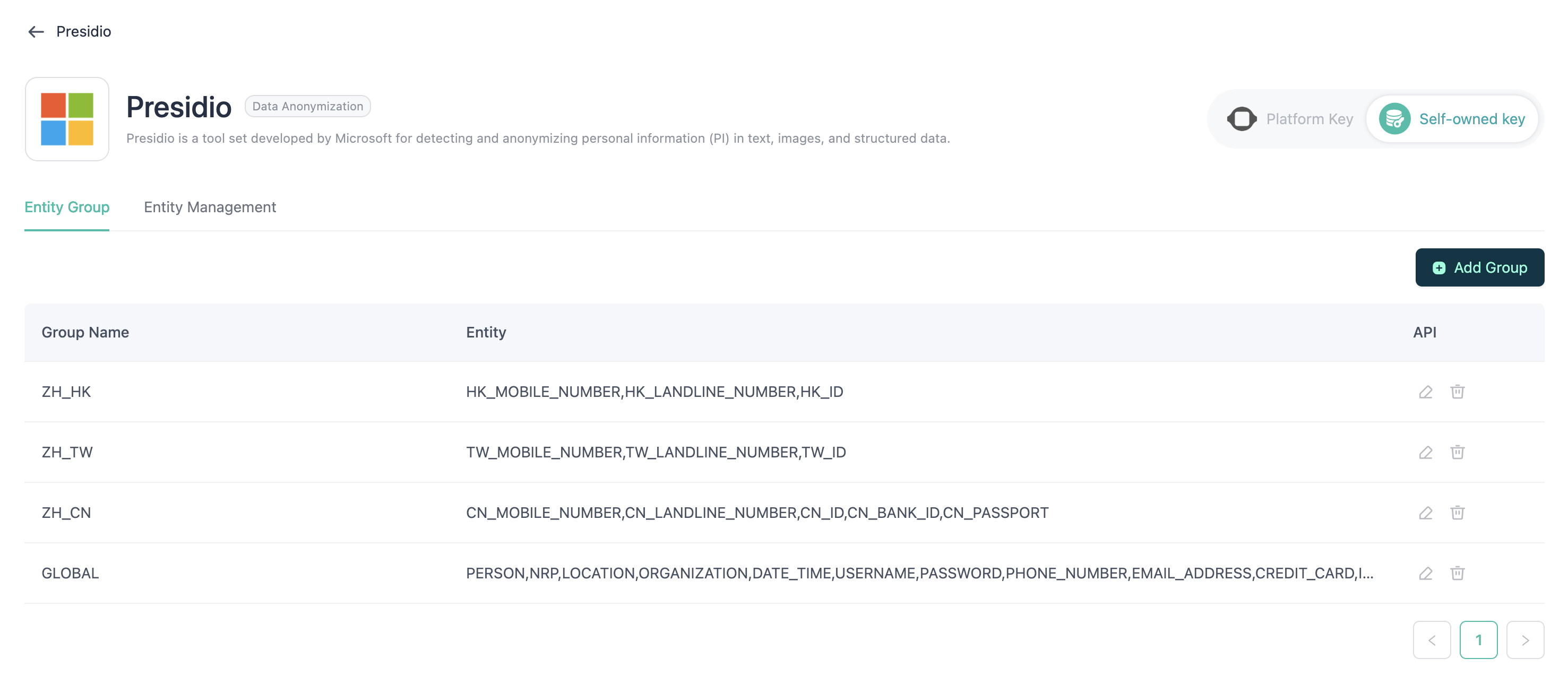
Las diferentes entidades se pueden agrupar en categorías independientes, lo que facilita su selección y uso en los agentes.
Entidad
Una entidad se refiere al objeto de anonimización. GPTBots incluye compatibilidad nativa con un conjunto de entidades de uso común, pero también permite a los usuarios definir entidades personalizadas para satisfacer diversas necesidades de anonimización.
Nueva entidad
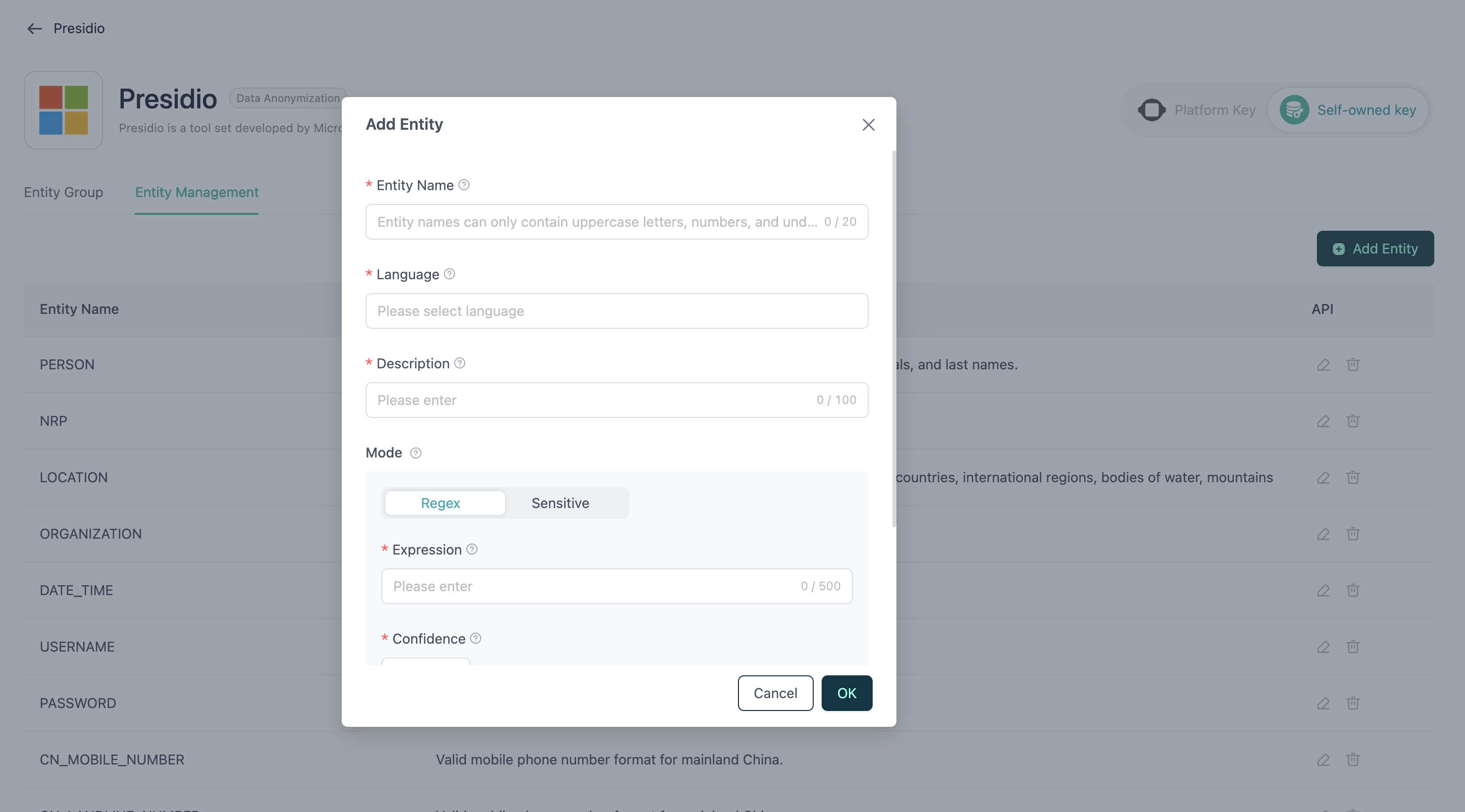
- Nombre: El nombre de la entidad, que solo puede contener letras mayúsculas y guiones bajos.
- Idioma: Los idiomas compatibles con la entidad. Una sola entidad puede admitir varios idiomas.
- Descripción: Una breve introducción o explicación de la entidad.
- Patrón regex: Una expresión regular utilizada para hacer coincidir la entidad.
- Puntuación (confianza): El nivel de confianza de la coincidencia, en un rango de 0,0 a 1,0.
- Palabras sensibles: Una lista de palabras o frases exactas que se identificarán como esta entidad si están presentes en el texto.
- Contexto: Una lista de palabras clave contextuales que ayudan a aumentar la puntuación de coincidencia. Si estas palabras aparecen cerca de una posible coincidencia en el texto, Presidio asignará una puntuación de confianza más alta a la coincidencia.