1. Qué son los «Eventos Clave»
Los «Eventos Clave» son la capacidad de memoria de negocio a largo plazo integrada en GPTBots: durante las conversaciones multironda entre el usuario y el Bot, la plataforma invoca al LLM para identificar automáticamente, dentro de la conversación, los eventos con valor de negocio (como retiradas, reclamaciones, citas, reembolsos…), los almacena de forma estructurada en la dimensión de usuario y, en conversaciones posteriores, los reinyecta como contexto en el Bot, permitiéndole «recordar» qué le ocurrió antes a ese usuario y en qué fase está cada evento actual.
Los problemas centrales que resuelve son:
- Pérdida de memoria entre conversaciones: los LLM tradicionales solo ven la ventana de memoria a corto plazo de la conversación actual, por lo que las acciones clave de negocio se olvidan en conversaciones largas o entre conversaciones distintas.
- Consolidación de datos estructurados: convierte conversaciones dispersas en un flujo de eventos consultable, computable y auditable, reutilizable por riesgo, control de calidad de atención al cliente y perfiles de usuario.
- Seguimiento del avance de estado: cada evento tiene un estado
PENDING / IN_PROGRESS / RESOLVED / CLOSEDy puede progresar de forma continuada a través de varias conversaciones.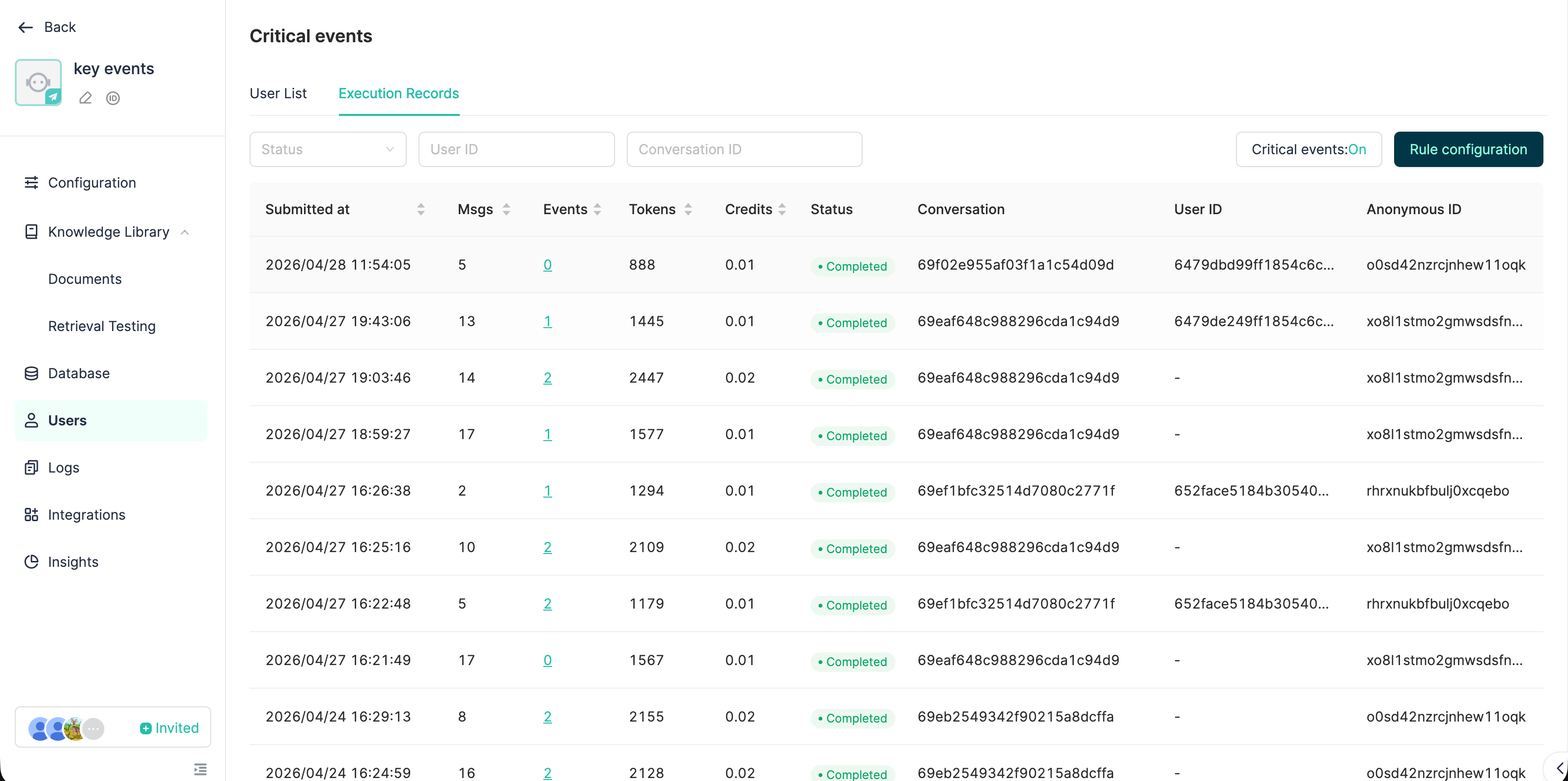
2. Filosofía de diseño
1. Convertir la "conversación" en un "flujo de eventos"
La conversación es no estructurada y los eventos son estructurados. Los eventos clave traducen "lo que el usuario ha dicho y hecho" en registros con la forma «categoría + resumen + entidades + estado + prioridad + confianza», permitiendo que sistemas externos al LLM (estadísticas, riesgo, control de calidad humano) también puedan consumir esa memoria.
2. Doble vía de disparo, evitando tanto omisiones como excesos
Dentro de una sola conversación, los eventos pueden aparecer a mitad de camino o requerir una extracción posterior tras la salida del usuario. El sistema utiliza un esquema de tres niveles: umbral de mensajes (tiempo real) + tiempo de inactividad (lote) + disparo manual (red de seguridad), de modo que los desarrolladores puedan ajustar parámetros para equilibrar coste y latencia.
3. Extracción con LLM activada por defecto, con posibilidad de degradar a modelos económicos
La extracción de eventos requiere inferencia con LLM y consume Token. Por ello, el modelo de extracción y el modelo principal de conversación del Bot se pueden configurar de forma independiente: por ejemplo, usar Claude / GPT para la conversación principal y un modelo pequeño más barato para la extracción, con tarificación y optimización separadas.
4. Doble vía de identidad como red de seguridad
Los eventos se agregan por usuario. Se usa de forma prioritaria el userId (identificador de mayor jerarquía) que el desarrollador transmite; cuando falta, se recurre al anonymousId generado por la plataforma (por ejemplo, para usuarios no autenticados). Aunque el desarrollador no envíe userId, las conversaciones de visitantes anónimos también pueden acumular eventos.
5. Aislamiento estricto del ámbito de usuario, evitando contaminación por alucinaciones del LLM
El LLM, al ejecutar UPDATE / DELETE / MERGE, puede "inventarse" un eventId perteneciente a otro usuario. Internamente, el código realiza una verificación matchesUserScope por cada operación, imponiendo el userId / anonymousId como filtro estricto, con el fin de evitar la contaminación de eventos entre usuarios.
6. Inyección en el Prompt mediante dos vías: explícita e implícita
- Explícita: en el Prompt se escribe el marcador
{{key_event_<eventType>}}, recogiendo el valor exacto por tipo de evento. - Implícita: si no se escribe el marcador, se añade automáticamente la sección
## Recent Key Eventsal final del Prompt, con cero configuración.
3. Principios fundamentales
3.1 Modelo de datos
| Rol | Notas |
|---|---|
| Tabla principal de eventos clave | Indexación multidimensional por usuario / tipo / fecha |
| Configuración a nivel de Bot (única por Bot) | Controla interruptor, umbrales y reglas de extracción |
| Estado de extracción a nivel de conversación | Registra mensajes pendientes de extraer, tiempo de inactividad, estado de concurrencia |
| Registros de ejecución de extracción | Auditoría de cada extracción + consumo de Token / créditos |
3.2 Mecanismo de disparo en tres niveles
flowchart TB
subgraph L1["Nivel 1: disparo en tiempo real"]
direction TB
A1["Cada mensaje del usuario<br/>pendingMessageCount +1"] --> A2{"pendingMessageCount<br/>≥ messageThreshold ?"}
end
subgraph L2["Nivel 2: disparo por inactividad"]
direction TB
B1["Escaneo programado<br/>cada 30 / 60 / 300 segundos"] --> B2{"lastMessageTime > idleTimeout antes<br/>Y pendingMessageCount > 0<br/>Y extractionStatus == IDLE"}
end
subgraph L3["Nivel 3: disparo manual"]
direction TB
C1["POST /bot/event/execute/.../retry<br/>o clic en Reintentar en la página de registros"]
end
LLM(["Invocar al LLM para extraer"])
A2 -->|Sí| LLM
B2 -->|Todas cumplen| LLM
C1 --> LLM
3.3 Cómo aplicar los eventos clave
- El módulo de memoria incorpora el control de eventos clave: el componente memory puede leer y recordar eventos clave. Puede habilitar eventos clave y personalizar los tipos de eventos clave y la cantidad que se utilizan.
- Los nodos impulsados por LLM en FlowAgent ya admiten la activación de eventos clave desde el módulo de memoria, mejorando la capacidad de enrutamiento del clasificador, la precisión de las respuestas del LLM y la precisión de los nodos de juicio.
- Se admite la referencia de variables mediante «Variables globales – Eventos clave»; las ramas If/else pueden encaminar según el tipo de evento clave.
3.4 Mecanismo de inyección
Modo A: añadido automático (cero configuración)
Cuando el Bot tiene activados los eventos clave y en el Prompt no aparece el marcador {{key_event_*}}, antes de cada llamada al LLM el sistema añade automáticamente al final del Prompt los últimos N eventos en el siguiente formato:
## Recent Key Events
eventType: withdrawal | summary: El usuario solicita retirar 5000 € | status: en curso | priority: alta | confidence: alta | updateTime: 2026-04-28 09:21:33 | entities: {"amount":5000,"channel":"bank"}
eventType: complaint | summary: El usuario se queja de la lentitud de respuesta del servicio de atención | status: resuelto | priority: media | confidence: media | updateTime: 2026-04-27 18:02:11
Modo B: sustitución de marcadores (control preciso)
En el Prompt / componente de flujo / regla se escribe:
{{key_event_withdrawal}} ← solo inyecta eventos de "retirada"
{{key_event_complaint}} ← solo inyecta eventos de "reclamación"
La plataforma genera variables agrupadas por eventType, y los tipos de evento que no coincidan no se inyectarán. Se inyectan como máximo 30 eventos por variable.
Flow Bot: control independiente a nivel de componente
Cada nodo LLM del flujo de trabajo dispone de su propia FlowKeyEventConfig: se puede activar o desactivar de forma independiente, seleccionar tipos de evento específicos y fijar recentEventCount (5 por defecto). Dentro de la misma conversación, los eventos solo se consultan una vez (cacheados en ChatContext) y los varios nodos comparten esos datos.
4. Guía de uso
4.1 Activación en el panel de configuración del Bot
Ruta de acceso: Consola de desarrollador → Detalle del Bot → Gestión de Usuarios (User Manage) → panel lateral «Eventos clave»
Pasos:
- Activar el interruptor general.
- Modelo de extracción: opcional; si no se selecciona, se utiliza el modelo de conversación por defecto del Bot. Se recomienda elegir un modelo económico (por ejemplo, GPT-4o-mini / serie Haiku).
- Reglas de extracción (≤2000 caracteres): describir en lenguaje natural al LLM «qué se considera un evento clave» en este escenario del Bot. Ejemplo:Extraer únicamente acciones de negocio relacionadas con dinero (retiradas, depósitos, transferencias, reembolsos). Ignorar la conversación informal y las expresiones emocionales. Los campos de entidades deben incluir importe (amount), divisa (currency) y número de pedido (orderId).
Extraer únicamente acciones de negocio relacionadas con dinero (retiradas, depósitos, transferencias, reembolsos). Ignorar la conversación informal y las expresiones emocionales. Los campos de entidades deben incluir importe (amount), divisa (currency) y número de pedido (orderId).Este bloque de código en una ventana flotante - Número de eventos recientes (0
50): número de eventos a inyectar en el Prompt en cada conversación. 0 significa no inyectar; lo habitual es 510. - Momento de disparo:
- Umbral de mensajes (5~50): por defecto 10.
- Tiempo de inactividad (2~60 minutos): por defecto 3.
- Diccionario de categorías de evento (máximo 10): cada categoría incluye «nombre» (≤10 caracteres) y «descripción» (≤100 caracteres, indicando al LLM qué entra en esta categoría).
- Hacer clic en Guardar.
Aviso: una vez la categoría está en producción no conviene cambiarle el nombre — los eventos históricos seguirán almacenando el nombre antiguo, y aparecerá el caso en que
{{key_event_<nombre antiguo>}}no obtiene valor. El front-end mostrará un aviso naranja cuando la categoría ya exista.
4.2 Referenciar eventos en el Prompt
Prompt genérico de Bot
Eres un asistente de atención al cliente financiera.
【Movimientos de dinero recientes del usuario】
{{key_event_withdrawal}}
【Reclamaciones recientes del usuario】
{{key_event_complaint}}
Por favor, responde a las preguntas del usuario basándote en el contexto anterior.
Prompt de componente de Flow Bot
- Hacer clic en el nodo impulsado por LLM en el lienzo → en el panel de configuración localizar la sección «Memoria - Eventos clave».
- Marcar
enable, seleccionar los tipos de evento que el nodo debe inyectar y establecer el número de eventos recientes a recuperar (por defecto 5).
4.3 Monitorización de los registros de ejecución de extracción
Ruta de acceso: Consola de desarrollador → Detalle del Bot → Gestión de Usuarios → pestaña Registros de ejecución
Información visible:
- Estado de cada extracción (PENDING / RUNNING / COMPLETED / FAILED)
- Origen del disparo (REALTIME / SCHEDULED / MANUAL)
- Número de mensajes procesados / número de eventos extraídos
- Consumo de Token / consumo de créditos
- Motivo del fallo + botón «Reintentar»
- Panel de detalle: lista todos los eventos creados / modificados en esa extracción.
4.4 Facturación y tarificación
Los costes de las llamadas al LLM derivadas de los eventos clave se contabilizan en la partida Eventos clave de la factura, separada del consumo del flujo principal de conversación, lo que facilita controlar el coste de forma independiente.
5. Escenarios típicos de aplicación
| Escenario | Ejemplos de tipos de evento | Valor |
|---|---|---|
| Atención al cliente financiera / pagos internacionales | withdrawal retirada / deposit depósito / kyc autenticación de identidad / dispute disputa |
Seguimiento de movimientos de dinero entre conversaciones; los equipos de riesgo y de atención humana ven de un vistazo el flujo histórico de negocio del usuario |
| Posventa de comercio electrónico | refund reembolso / return devolución / complaint reclamación |
Mantenimiento automático de la máquina de estados de posventa, con avance continuo a lo largo de varias conversaciones |
| Citas / planificación | appointment cita / cancellation cancelación |
Permite al Bot recordar cuántas veces el usuario ha cambiado la hora y cuál es la franja confirmada actualmente |
| Asistente de RR. HH. / IT interno | leave_request solicitud de permiso / it_ticket ticket |
Convertir la conversación en un flujo de tickets consultable |
| Educación / acompañamiento al aprendizaje | homework_submission / quiz_score / weak_topic |
Registro a largo plazo del estado de aprendizaje del estudiante para generar planes de repaso personalizados |
| Salud / consulta sanitaria | symptom síntoma / medication medicación / appointment revisión |
Conservar la información del historial entre consultas, mejorando la coherencia del diagnóstico |
6. Mejores prácticas
Capa de configuración
- Escribir descripciones en el diccionario de categorías: hay que rellenar tanto
namecomodescription. El LLM se basa principalmente endescriptionpara decidir «si esta conversación pertenece a esta categoría». Dejardescriptionvacío reduce notablemente la precisión de la clasificación. - Mantener el número de categorías entre 5 y 10. Un exceso de categorías hace que el LLM dude al clasificar y aumenta el tamaño del Prompt. Conviene fusionar sinónimos («retirada» y «extracción» en una sola).
- Las reglas de extracción deben describir tanto «qué hacer» como «qué no hacer». Por ejemplo:Extraer solo acciones de negocio confirmadas como completadas o en curso. Excluir: discusiones hipotéticas («¿y si...?»), emociones puras y conversación informal.
Extraer solo acciones de negocio confirmadas como completadas o en curso. Excluir: discusiones hipotéticas («¿y si...?»), emociones puras y conversación informal.Este bloque de código en una ventana flotante - Elegir un modelo de extracción pequeño en lugar de uno grande. La extracción es una tarea de salida estructurada con bajos requisitos de razonamiento. GPT-4o-mini / Claude Haiku / DeepSeek-V3 suelen ser suficientes, con un coste por llamada que puede ser un orden de magnitud menor que el del modelo de conversación principal.
- No fijar inicialmente
recentEventCountal máximo. Inyectar demasiados eventos consume contexto del flujo principal. Comenzar por 5 y aumentar solo si el Bot «no recuerda» con frecuencia.
Parámetros de disparo
- Conversaciones largas / escenarios de atención al cliente:
messageThreshold = 10yidleTimeoutMinutes = 3suelen ser adecuados. - Interacciones cortas / Bots orientados a tareas: bajar
idleTimeoutMinutesa 2, para evitar que la extracción de eventos se demore demasiado al terminar la conversación. - Conversaciones de alta frecuencia y bajo valor (como QA general): subir
messageThresholda 20~30 para evitar disparar el LLM en cada turno y disparar el coste.
Referencias en el Prompt
- Usar marcadores con preferencia sobre el añadido automático. Los marcadores son controlables y pueden segmentarse con precisión por tipo; el añadido automático encaja mejor en escenarios de red de seguridad donde «se quiere todo».
- No activar todos los nodos en Flow Bot. Activarlos solo en los nodos que realmente necesitan contexto de eventos (por ejemplo, nodos de respuesta de atención al cliente o de juicio de riesgo); los nodos de detección de intenciones / enrutamiento no lo necesitan.
- Evitar que
{{key_event_xxx}}aparezca en la parte superior del Prompt de sistema: los eventos históricos suelen crecer con el tiempo y, si revientan el límite de Token, las instrucciones principales serán truncadas. Se recomienda situarlo en la parte intermedia del Prompt o antes de los Few-shot.
Gobierno de datos
- Revisar manualmente de forma periódica los eventos con confianza LOW. El LLM también extrae el contenido «afirmado únicamente por el usuario»; el equipo de negocio debe filtrarlo, por ejemplo con
confidence=LOW+disputeFlag=true. - Combinar la escritura por API en flujos importantes. Cuando el sistema de pedidos ya dispone de datos estructurados, escribir directamente con
createdBy=APIes más preciso que dejar que el LLM extraiga de la conversación, y puede coexistir con los resultados extraídos por LLM. - Usar la operación MERGE con cuidado. Ocasionalmente el LLM fusionará eventos que no debería. Se recomienda vigilar las operaciones MERGE en los registros de ejecución y, si es necesario, restaurar mediante API separando los eventos.
- Aprovechar el campo
entities. En las reglas de extracción, exigir explícitamente al LLM que extraiga KV clave (importes, números de pedido, fechas, etc.); luego se podrán hacer consultas estructuradas directamente, lo cual es más fiable que parsear el texto delsummary.
Lista de diagnóstico
| Síntoma | Ruta de diagnóstico |
|---|---|
| No se extraen eventos | ① ¿Está activado el interruptor general? ② ¿Tiene el Bot saldo de créditos? ③ ¿Hay registros con FAILED? ④ ¿Son las reglas de extracción demasiado estrictas? |
| El contenido de un tipo de evento clave está vacío | ① ¿Tiene el usuario eventos de ese tipo? ② ¿Se ha creado correctamente ese tipo de evento? ③ ¿Es coherente la ortografía del nombre de la categoría? |
| Mezcla de información entre usuarios | Verificar que se ha enviado el userId correcto; en usuarios sin login, comprobar que el anonymousId es estable |
| Coste de extracción demasiado alto | ① Reducir la frecuencia de extracción ② Cambiar a un modelo de extracción más barato |
| Resultados de extracción mal clasificados | ① Mejorar las descripciones de las categorías ② Añadir varios ejemplos few-shot en las reglas de extracción |
7. Límites y advertencias
- La extracción no es en tiempo real. Incluso el disparo de Nivel 1 (tiempo real) solo ocurre cuando los mensajes alcanzan el umbral. Los procesos de negocio que requieren consistencia fuerte (como transacciones) no deben basar sus decisiones en el flujo de eventos: los eventos son una memoria auxiliar, no la fuente de verdad.
- La ventana de extracción es como máximo de 100 mensajes (
MAX_MESSAGES_PER_BATCH). Las conversaciones muy largas se dividen en varias ventanas; las relaciones causales entre ventanas se recuperan mediante la «comparación con eventos históricos». - Las consultas de eventos tienen un timeout de protección de 500 ms. Las consultas lentas no ralentizarán la cadena de chat, pero en casos extremos puede no inyectarse ningún evento.
- El ID anónimo se reinicia tras una limpieza del cliente. Cuando un usuario anónimo cambia de dispositivo o limpia la caché, se considera un usuario nuevo y los eventos no le seguirán.
- En el modo multi-agent el flujo de eventos no participa (véase la declaración de obsolescencia en oversea-ailab CLAUDE.md).