Anonymisation des Données
L'anonymisation des données fait référence au processus d'anonymisation des informations personnelles identifiables (PII) saisies par les utilisateurs, garantissant que les informations sensibles des utilisateurs ne sont pas accessibles aux services LLM et protégeant la vie privée des utilisateurs.
Processus
graph LR
Input --> Anonymization --> LLM --> Deanonymization --> Output
Configuration
Actuellement, seul le service d'anonymisation Microsoft Presidio est disponible.
Groupe
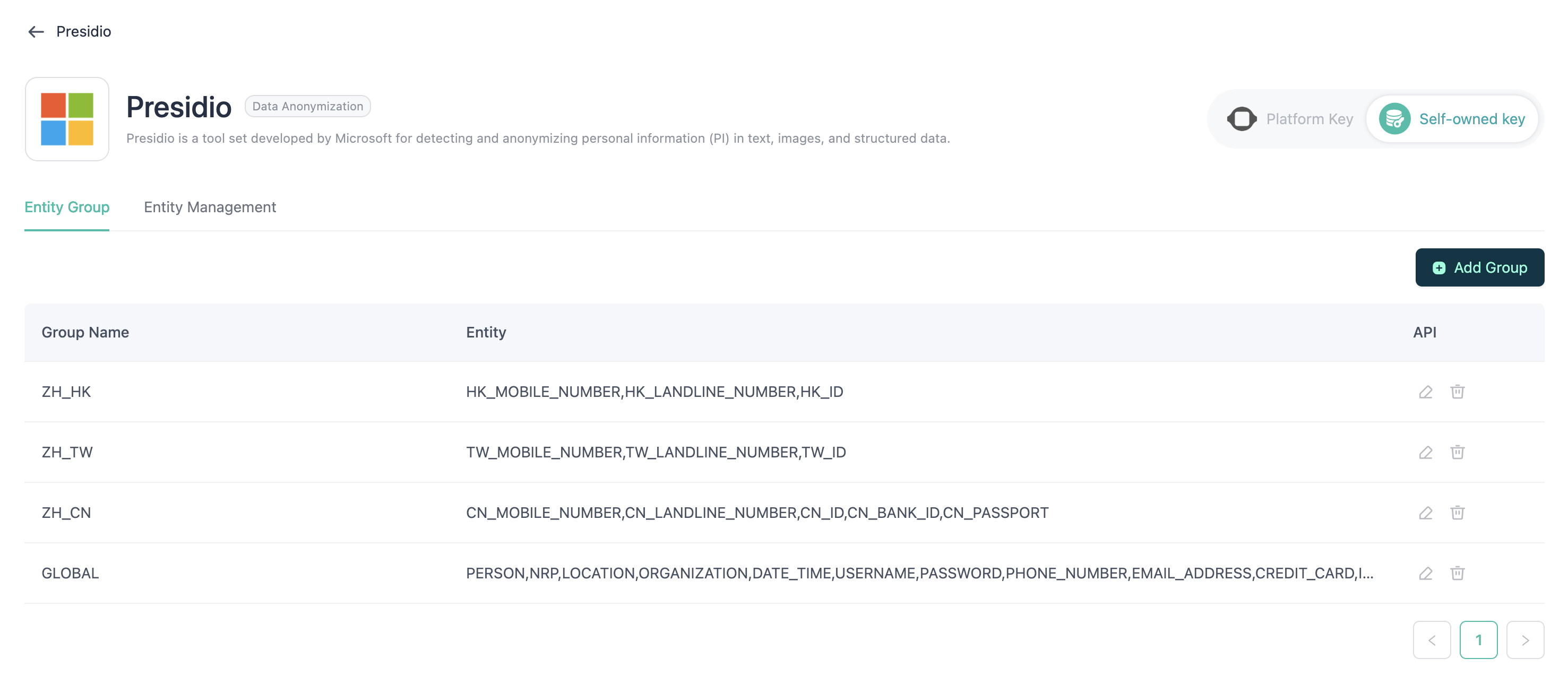
Différentes entités peuvent être regroupées dans des catégories distinctes, ce qui facilite leur sélection et leur utilisation au sein des agents.
Entité
Une entité fait référence à l'objet de l'anonymisation. GPTBots prend en charge un ensemble d'entités couramment utilisées, mais permet également aux utilisateurs de définir des entités personnalisées pour répondre à divers besoins d'anonymisation.
Nouvelle Entité
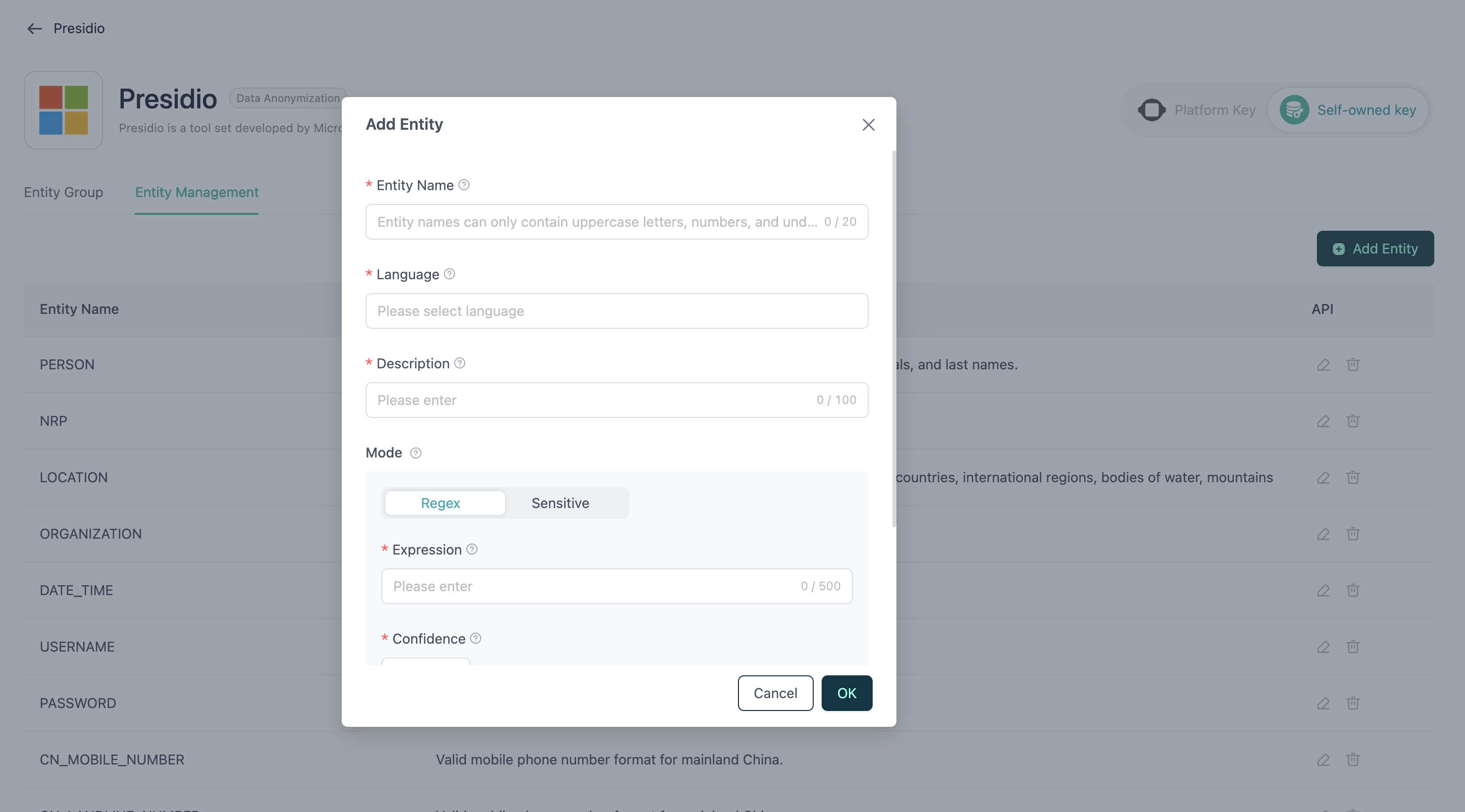
- Nom : Le nom de l'entité, qui ne peut contenir que des lettres majuscules et des underscores.
- Langue : La ou les langues prises en charge par l'entité. Une même entité peut prendre en charge plusieurs langues.
- Description : Une brève introduction ou explication de l'entité.
- Motif Regex : Une expression régulière utilisée pour détecter l'entité.
- Score (Confiance) : Le niveau de confiance de la correspondance, allant de 0,0 à 1,0.
- Mots Sensibles : Une liste de mots ou d'expressions exacts qui seront identifiés comme cette entité s'ils sont présents dans le texte.
- Contexte : Une liste de mots-clés contextuels qui aident à augmenter le score de correspondance. Si ces mots apparaissent près d'une correspondance potentielle dans le texte, Presidio attribuera un score de confiance plus élevé à la correspondance.