1. Was sind „Schlüsselereignisse"
„Schlüsselereignisse" sind die in GPTBots integrierte Fähigkeit zur langfristigen Geschäftsspeicherung: Während der mehrteiligen Konversation zwischen Benutzer und Bot ruft die Plattform ein LLM auf, um automatisch geschäftlich wertvolle Ereignisse aus dem Dialog zu erkennen (z. B. Auszahlungen, Beschwerden, Termine, Rückerstattungen ...), sie strukturiert nach Benutzerdimension zu speichern und sie in nachfolgenden Konversationen als Kontext an den Bot zurückzuspeisen, sodass der Bot „sich erinnert", was diesem Benutzer in der Vergangenheit widerfahren ist und in welchem Bearbeitungsstand sich das aktuelle Ereignis befindet.
Die Kernprobleme, die gelöst werden:
- Fehlende sitzungsübergreifende Erinnerung: Herkömmliche LLMs sehen nur das Kurzzeitgedächtnis-Fenster der aktuellen Sitzung; in sitzungsübergreifenden oder langen Sitzungen werden wichtige Geschäftsaktionen vergessen.
- Aufbau strukturierter Daten: Die Verdichtung verstreuter Dialoge zu einem abfragbaren, statistisch auswertbaren und prüfbaren Ereignisstrom für Risikokontrolle, Kundenservice-Qualitätssicherung und Wiederverwendung von Benutzerprofilen.
- Verfolgung des Statusverlaufs: Jedes Ereignis hat einen Status
PENDING / IN_PROGRESS / RESOLVED / CLOSEDund kann über mehrere Konversationen hinweg kontinuierlich vorangetrieben werden.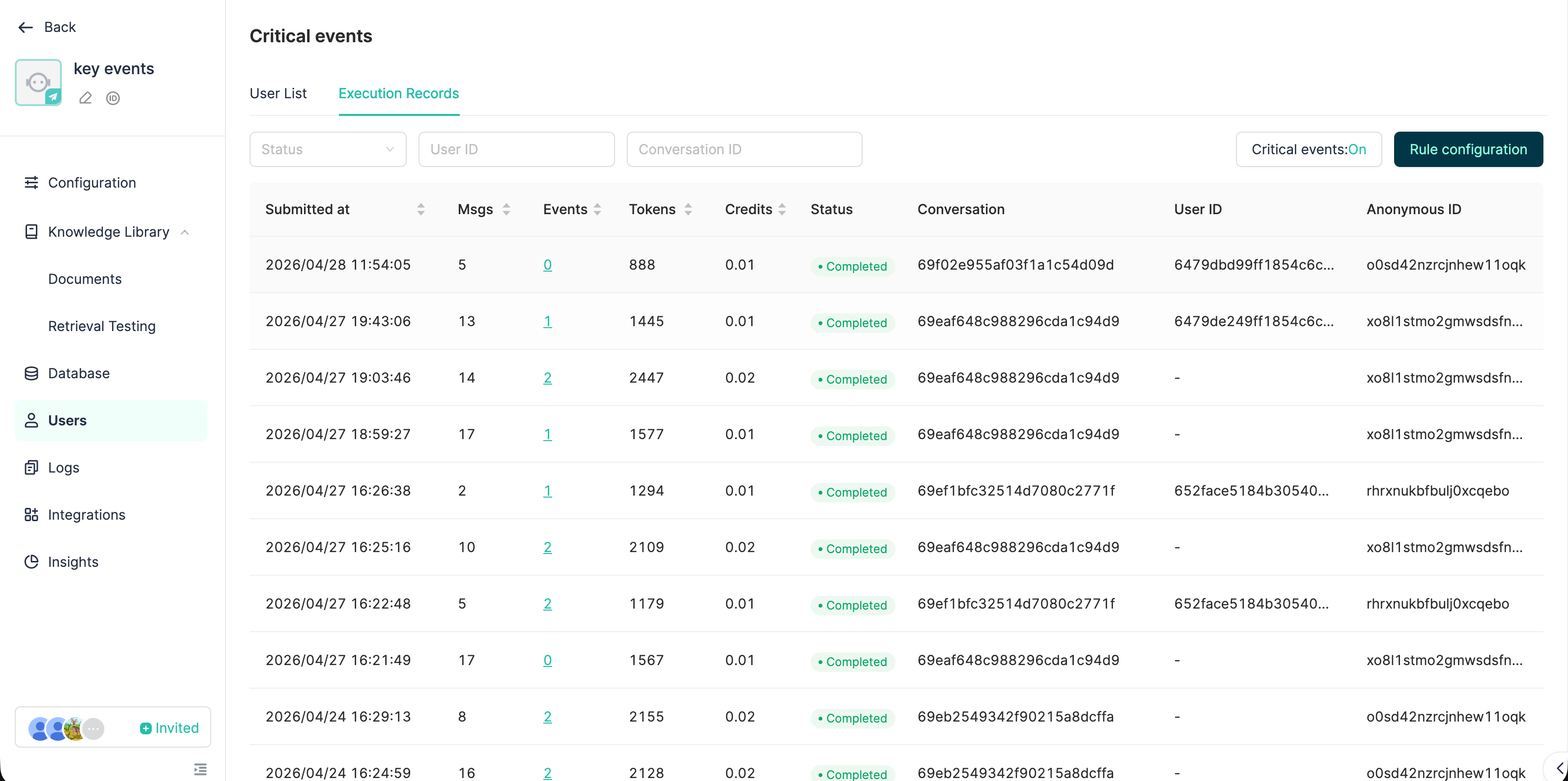
2. Designphilosophie
1. „Dialoge" zu „Ereignisströmen" verdichten
Dialoge sind unstrukturiert, Ereignisse sind strukturiert. Schlüsselereignisse übersetzen „was der Benutzer gesagt hat, was der Benutzer getan hat" in Ereignisaufzeichnungen mit „Kategorie + Zusammenfassung + Entitäten + Status + Priorität + Konfidenz", sodass auch nachgelagerte Systeme jenseits des LLM (Statistik, Risikokontrolle, manuelle Qualitätssicherung) diese Erinnerung konsumieren können.
2. Zwei-Spuren-Auslösung, weder Auslassungen noch Übermaß
In einer einzelnen Konversation können Ereignisse mitten im Verlauf auftreten oder erst nach dem Verlassen des Benutzers nachgeholt werden müssen. Das System verwendet ein dreistufiges Schema aus Nachrichtenschwellwert (Echtzeit) + Leerlauf-Timeout (Batch) + manuelle Auslösung (Auffanglösung), wobei Entwickler die Parameter zur Abwägung von Kosten und Aktualität anpassen können.
3. LLM-Extraktion standardmäßig aktiviert, herabstufbar auf günstige Modelle
Die Ereignisextraktion selbst erfordert LLM-Inferenz und verbraucht Tokens. Daher können Extraktionsmodell und Hauptdialogmodell des Bots unabhängig konfiguriert werden – das Hauptgespräch kann z. B. Claude / GPT verwenden, die Extraktion ein günstigeres kleineres Modell, mit separater Abrechnung und separater Optimierung.
4. Doppelte Absicherung der Benutzeridentität
Ereignisse werden nach Benutzerdimension aggregiert. Vorrangig wird die vom Entwickler übergebene userId verwendet (höchste Kennung); fehlt diese, wird auf die von der Plattform erzeugte anonymousId zurückgegriffen (z. B. bei nicht angemeldeten Benutzern). Selbst wenn der Entwickler keine userId übergibt, kann die Ereignisakkumulation auch in Dialogen anonymer Besucher abgeschlossen werden.
5. Strikte Isolation des Benutzerbereichs zur Vermeidung von LLM-Halluzinationen
Das LLM kann bei UPDATE / DELETE / MERGE „erfundene" eventIds anderer Benutzer ausgeben. Der Code führt intern für jede Operation eine matchesUserScope-Validierung durch und erzwingt userId / anonymousId als harte Filterbedingungen, um eine benutzerübergreifende Ereignisverunreinigung zu verhindern.
6. Prompt-Injektion über zwei Pfade: explizit + implizit
- Explizit: Schreiben Sie den Platzhalter
{{key_event_<eventType>}}im Prompt, um Werte präzise nach Ereignistyp abzurufen. - Implizit: Wenn kein Platzhalter geschrieben wird, wird automatisch der Abschnitt
## Recent Key Eventsan das Ende des Prompts angehängt – nutzbar ohne Konfiguration.
3. Kernprinzip
3.1 Datenmodell
| Rolle | Anmerkung |
|---|---|
| Haupttabelle der Schlüsselereignisse | Mehrdimensionaler Index nach Benutzer/Typ/Zeit |
| Bot-Ebene-Konfiguration (eindeutig pro Bot) | Steuert Schalter, Schwellenwerte, Extraktionsregeln |
| Sitzungsbezogener Extraktionsstatus | Zeichnet ausstehende Nachrichtenanzahl, Leerlaufzeit und Nebenläufigkeitsstatus auf |
| Extraktions-Ausführungsprotokoll | Audit + Token / Punkteverbrauch jeder Extraktion |
3.2 Dreistufiger Auslösemechanismus
flowchart TB
subgraph L1["Level 1: Echtzeit-Auslöser"]
direction TB
A1["Jede Benutzernachricht<br/>pendingMessageCount +1"] --> A2{"pendingMessageCount<br/>≥ messageThreshold ?"}
end
subgraph L2["Level 2: Leerlauf-Auslöser"]
direction TB
B1["Geplanter Scan<br/>alle 30 / 60 / 300 Sekunden"] --> B2{"lastMessageTime > idleTimeout zurück<br/>UND pendingMessageCount > 0<br/>UND extractionStatus == IDLE"}
end
subgraph L3["Level 3: Manuelle Auslösung"]
direction TB
C1["POST /bot/event/execute/.../retry<br/>oder Wiederholen auf der Ausführungsseite"]
end
LLM(["LLM-Extraktion aufrufen"])
A2 -->|Ja| LLM
B2 -->|Alle erfüllt| LLM
C1 --> LLM
3.3 Schlüsselereignisse anwenden
- Das Speichermodul unterstützt jetzt die Steuerung von Schlüsselereignissen: Die memory-Komponente kann Schlüsselereignisse lesen und sich daran erinnern. Sie können Schlüsselereignisse aktivieren und die zu verwendenden Ereignistypen und Anzahl anpassen.
- LLM-gesteuerte Knoten im FlowAgent unterstützen bereits die Aktivierung von Schlüsselereignissen aus dem Speichermodul und verbessern dadurch die Routing-Fähigkeit des Classifiers, die Genauigkeit der LLM-Antworten sowie die Genauigkeit von Entscheidungsknoten.
- Variablenreferenzen über „Globale Variablen – Schlüsselereignisse" werden unterstützt; If/else-Verzweigungen können nach Schlüsselereignistyp routen.
3.4 Injektionsmechanismus
Modus A: Automatisches Anhängen (ohne Konfiguration)
Wenn der Bot Schlüsselereignisse aktiviert hat und im Prompt kein Platzhalter {{key_event_*}} vorkommt, hängt das System vor jedem LLM-Aufruf der Konversation die letzten N Ereignisse automatisch im folgenden Format an das Ende des Prompts an:
## Recent Key Events
eventType: withdrawal | summary: 用户申请提现 5000 元 | status: 处理中 | priority: 高 | confidence: 高 | updateTime: 2026-04-28 09:21:33 | entities: {"amount":5000,"channel":"bank"}
eventType: complaint | summary: 用户投诉客服响应慢 | status: 已解决 | priority: 中 | confidence: 中 | updateTime: 2026-04-27 18:02:11
Modus B: Platzhalter-Ersetzung (präzise Steuerung)
Im Prompt / in Workflow-Komponenten / in Regeln schreiben:
{{key_event_withdrawal}} ← Nur Ereignisse vom Typ „Auszahlung" injizieren
{{key_event_complaint}} ← Nur Ereignisse vom Typ „Beschwerde" injizieren
Die Plattform erzeugt entsprechende Variablen gruppiert nach eventType; nicht zugeordnete Ereignistypen werden nicht injiziert. Maximal 30 Einträge pro Variable.
Flow Bot: Komponentenebene mit unabhängiger Steuerung
Jeder LLM-Knoten im Workflow hat seine eigene FlowKeyEventConfig: separater Schalter, separate Auswahl der Ereignistypen und separate Einstellung von recentEventCount (standardmäßig 5). Innerhalb derselben Sitzung werden Ereignisse nur einmal abgefragt (Cache in ChatContext); mehrere Knoten teilen sich die Daten.
4. Bedienungsanleitung
4.1 Aktivierung im Bot-Konfigurationspanel
Pfad: Entwicklerkonsole → Bot-Details → Benutzerverwaltung (User Manage) → Drawer „Schlüsselereignisse"
Bedienungsschritte:
- Hauptschalter einschalten
- Extraktionsmodell: Optional; ohne Auswahl wird das Standarddialogmodell des Bots verwendet. Empfohlen wird ein günstiges Modell (z. B. GPT-4o-mini / Haiku-Reihe).
- Extraktionsregel (≤ 2000 Zeichen): Beschreiben Sie dem LLM in natürlicher Sprache, „was in diesem Bot-Szenario als Schlüsselereignis gilt". Beispiel:Nur Geschäftsaktionen im Zusammenhang mit Geld extrahieren (Auszahlung, Einzahlung, Überweisung, Rückerstattung). Smalltalk und emotionale Ausdrücke ignorieren. Die Entitätsfelder müssen Betrag (amount), Währung (currency) und Bestellnummer (orderId) enthalten.
Nur Geschäftsaktionen im Zusammenhang mit Geld extrahieren (Auszahlung, Einzahlung, Überweisung, Rückerstattung). Smalltalk und emotionale Ausdrücke ignorieren. Die Entitätsfelder müssen Betrag (amount), Währung (currency) und Bestellnummer (orderId) enthalten.Dieser Codeblock im schwebenden Fenster - Anzahl der letzten Ereignisse (0–50): Anzahl der pro Konversation in den Prompt injizierten Ereignisse. 0 bedeutet keine Injektion, üblich sind 5–10.
- Auslösezeitpunkt:
- Nachrichtenschwellwert (5–50): Standard 10.
- Leerlauf-Timeout (2–60 Minuten): Standard 3.
- Ereigniskategorie-Wörterbuch (max. 10 Einträge): Jede Kategorie enthält „Name" (≤ 10 Zeichen) und „Beschreibung" (≤ 100 Zeichen, sagt dem LLM, was diese Kategorie umfasst).
- Auf Speichern klicken.
⚠️ Warnung: Kategorienamen sollten nach dem Live-Gang nicht beliebig umbenannt werden – historische Ereignisse speichern weiterhin den alten Namen, was dazu führen kann, dass
{{key_event_<alter_name>}}keinen Wert liefert. Das Frontend zeigt eine orange Warnung an, wenn die Kategorie bereits existiert.
4.2 Ereignisse im Prompt referenzieren
Allgemeiner Bot-Prompt
Sie sind ein Finanz-Kundenservice-Assistent.
[Letzte Geldtransaktionen dieses Benutzers]
{{key_event_withdrawal}}
[Letzte Beschwerden dieses Benutzers]
{{key_event_complaint}}
Bitte beantworten Sie die Fragen des Benutzers basierend auf dem obigen Kontext.
Flow Bot Komponenten-Prompt
- Klicken Sie im Canvas auf einen LLM-getriebenen Knoten → suchen Sie im Einstellungspanel die Konfiguration „Speicher – Schlüsselereignisse".
- Aktivieren Sie
enable, wählen Sie die Ereignistypen aus, die in diesem Knoten injiziert werden sollen, und stellen Sie die Anzahl der abzurufenden letzten Ereignisse ein (Standard: 5).
4.3 Überwachung der Extraktions-Ausführungsprotokolle
Pfad: Entwicklerkonsole → Bot-Details → Benutzerverwaltung → Reiter „Ausführungsprotokoll"
Sichtbare Informationen:
- Status jeder Extraktion (PENDING / RUNNING / COMPLETED / FAILED)
- Auslösequelle (REALTIME / SCHEDULED / MANUAL)
- Anzahl der verarbeiteten Nachrichten / Anzahl der extrahierten Ereignisse
- Token-Verbrauch / Punkteverbrauch
- Fehlerursache + Schaltfläche „Wiederholen"
- Detail-Drawer: Listet alle in dieser Extraktion erzeugten / geänderten Ereignisse auf
4.4 Abrechnung und Gebühren
Die LLM-Aufrufkosten für Schlüsselereignisse werden in der Rechnungsposition Schlüsselereignisse verbucht – getrennt von den Abzügen des Hauptdialogprozesses, um Kosten separat steuern zu können.
5. Typische Anwendungsszenarien
| Szenario | Beispiele für Ereignistypen | Mehrwert |
|---|---|---|
| Finanzwesen / grenzüberschreitender Zahlungs-Kundenservice | withdrawal Auszahlung / deposit Einzahlung / kyc Identitätsprüfung / dispute Streitfall |
Sitzungsübergreifende Verfolgung von Geldbewegungen; Risikokontrolle und manuelle Übernahme sehen den historischen Geschäftsverlauf des Benutzers auf einen Blick |
| E-Commerce-Kundendienst | refund Rückerstattung / return Rücksendung / complaint Beschwerde |
Automatische Pflege des Aftersales-Statusautomaten des Benutzers, kontinuierliche Fortschreibung über mehrere Konversationen |
| Termine / Planung | appointment Termin / cancellation Stornierung |
Der Bot erinnert sich, wie oft der Benutzer den Termin verschoben hat und welcher Zeitpunkt aktuell bestätigt ist |
| HR / interner IT-Assistent | leave_request Urlaubsantrag / it_ticket Ticket |
Verdichtung von Dialogen zu einem abfragbaren Ticketstrom |
| Bildung / Lernbegleitung | homework_submission / quiz_score / weak_topic |
Langfristige Aufzeichnung des Lernzustands des Schülers, Erstellung individueller Wiederholungspläne |
| Medizin / Gesundheitsberatung | symptom Symptom / medication Medikation / appointment Folgetermin |
Erhalt der Krankheitsverlaufsinformationen über mehrere Beratungen, Verbesserung der Konsistenz der Anamnese |
6. Bewährte Praktiken
✅ Konfigurationsebene
- Beschreibung im Kategorie-Wörterbuch verfassen – sowohl
nameals auchdescriptionmüssen ausgefüllt werden. Das LLM beurteilt vor allem anhand derdescription, „ob dieser Dialog zu dieser Kategorie gehört". Eine leeredescriptionsenkt die Klassifikationsgenauigkeit erheblich. - Anzahl der Kategorien auf 5–10 begrenzen. Zu viele Kategorien führen dazu, dass das LLM bei der Extraktion mit der Zuordnung ringt und der Prompt aufgebläht wird. Synonyme Kategorien zusammenführen („Auszahlung" und „Abhebung" als eine).
- In Extraktionsregeln „was tun" und „was nicht tun" beschreiben. Beispiel:Nur bestätigte abgeschlossene oder laufende Geschäftsaktionen extrahieren. Ausschließen: hypothetische Diskussionen („Was, wenn ..."), reine Emotionen, Smalltalk.
Nur bestätigte abgeschlossene oder laufende Geschäftsaktionen extrahieren. Ausschließen: hypothetische Diskussionen („Was, wenn ..."), reine Emotionen, Smalltalk.Dieser Codeblock im schwebenden Fenster - Bei Extraktionsmodellen lieber klein als groß. Die Extraktion ist eine Aufgabe der strukturierten Ausgabe und stellt geringe Anforderungen an die Schlussfolgerungsfähigkeit. GPT-4o-mini / Claude Haiku / DeepSeek-V3 reichen meist aus; die Einzelkosten können um eine Größenordnung niedriger liegen als beim Hauptdialogmodell.
recentEventCountnicht von Anfang an auf das Maximum setzen. Zu viele injizierte Ereignisse verdrängen den Hauptdialog-Kontext. Beginnen Sie mit 5; erhöhen Sie nur, wenn der Bot häufig „nichts erinnert".
✅ Auslöseparameter
- Lange Sitzungen / Kundenservice-Szenarien:
messageThreshold = 10,idleTimeoutMinutes = 3ist meist passend. - Kurze Interaktionen / aufgabenorientierte Bots: Reduzieren Sie
idleTimeoutMinutesauf 2, um zu verhindern, dass die Ereignisextraktion nach Gesprächsende verzögert wird. - Häufige, geringwertige Dialoge (z. B. einfache Q&A): Heben Sie
messageThresholdauf 20–30 an, um nicht in jeder Runde LLM-Extraktionen ausführen zu müssen und Kosten zu vermeiden.
✅ Prompt-Referenzierung
- Bevorzugen Sie Platzhalter statt sich auf das automatische Anhängen zu verlassen. Platzhalter sind steuerbar und können präzise nach Typ zugeschnitten werden; das automatische Anhängen eignet sich für Szenarien, in denen man „alles haben möchte".
- Nicht in jedem Knoten eines Flow Bots aktivieren. Aktivieren Sie es nur in Knoten, die wirklich Ereigniskontext benötigen (z. B. Kundenservice-Antwortknoten, Risikobewertungsknoten); für Intent-Erkennungs- / Routing-Knoten ist es nicht erforderlich.
- Vermeiden Sie
{{key_event_xxx}}an der Spitze des System-Prompts – historische Ereignisse wachsen im Laufe der Zeit; wenn sie das Token-Budget sprengen, werden Hauptanweisungen abgeschnitten. Empfehlung: in der Mitte des Prompts oder vor den Few-Shot-Beispielen platzieren.
✅ Datenverwaltung
- Ereignisse mit niedriger Konfidenz (LOW) regelmäßig manuell prüfen. Das LLM extrahiert auch Inhalte, die „nur einseitig vom Benutzer behauptet" wurden; die Geschäftsseite sollte sie filtern – etwa nach
confidence=LOW+disputeFlag=true. - Wichtige Geschäftsprozesse durch API-Schreibvorgänge ergänzen. Wenn das Bestellsystem bereits über strukturierte Daten verfügt, ist ein direktes Schreiben mit
createdBy=APIgenauer, als das LLM den Inhalt aus dem Dialog extrahieren zu lassen, und kann mit den LLM-Extraktionsergebnissen koexistieren. - MERGE-Operationen mit Vorsicht einsetzen. Das LLM führt gelegentlich Ereignisse zusammen, die nicht zusammengeführt werden sollten. Behalten Sie MERGE-Operationen im Ausführungsprotokoll im Auge und stellen Sie sie bei Bedarf über die API durch Aufteilen wieder her.
- Das Feld
entitiesclever nutzen. Verlangen Sie in den Extraktionsregeln explizit, dass das LLM die wichtigsten KVs (Betrag, Bestellnummer, Zeit usw.) extrahiert; spätere strukturierte Abfragen sind dann zuverlässiger als das Parsen dessummary-Texts.
⚠️ Checkliste zur Fehlersuche
| Phänomen | Suchpfad |
|---|---|
| Es werden keine Ereignisse extrahiert | ① Ist der Hauptschalter aktiviert ② Hat der Bot Punkteguthaben ③ Gibt es FAILED-Einträge im Ausführungsprotokoll ④ Sind die Extraktionsregeln zu streng |
| Inhalt eines bestimmten Schlüsselereignistyps ist leer | ① Hat der Benutzer Ereignisse dieses Typs ② Wurde der Ereignistyp korrekt erstellt ③ Ist der Kategoriename konsistent geschrieben |
| Benutzerübergreifende Vermischungen | Prüfen, ob die korrekte userId übergeben wurde; bei nicht angemeldeten Benutzern prüfen, ob die anonymousId stabil ist |
| Hohe Extraktionskosten | ① Extraktionsfrequenz senken ② Auf ein günstigeres Extraktionsmodell wechseln |
| Falsche Klassifizierung der Extraktionsergebnisse | ① Genauere Beschreibungen für die Kategorien hinterlegen ② In den Extraktionsregeln einige Few-Shot-Beispiele bereitstellen |
7. Fähigkeitsgrenzen und Hinweise
- Die Extraktion erfolgt nicht in Echtzeit. Selbst die Echtzeit-Auslösung der Stufe 1 wird erst ausgeführt, nachdem die Nachrichten den Schwellwert erreicht haben. Streng konsistente Geschäftsvorgänge (z. B. Transaktionen) dürfen sich nicht auf den Ereignisstrom für Entscheidungen verlassen – Ereignisse sind eine unterstützende Erinnerung, keine Quelle der Wahrheit.
- Das Extraktionsfenster umfasst maximal 100 Nachrichten (
MAX_MESSAGES_PER_BATCH). Übermäßig lange Sitzungen werden in mehrere Fenster aufgeteilt; fensterübergreifende Kausalbeziehungen werden über den „Abgleich mit historischen Ereignissen" wiederhergestellt. - Ereignisabfragen haben einen Schutz-Timeout von 500 ms. Langsame Abfragen verzögern den Chat-Pfad nicht, in Extremfällen erfolgt jedoch keine Ereignisinjektion.
- Anonyme IDs werden bei einer Bereinigung am Endgerät zurückgesetzt. Anonyme Benutzer, die das Gerät wechseln oder den Cache löschen, gelten als neuer Benutzer; Ereignisse folgen ihnen nicht.
- Im Multi-Agent-Modus nimmt der Ereignisstrom nicht teil (siehe die Verfallserklärung in der CLAUDE.md von oversea-ailab).